
Ad Tech Analysis Challenge
Recently, I did an analysis test for an advertising technology company I applied for. This post shows the notebook of codes and an one-pager of key findings.
I received a dataset that contains ~10,000 rows of user search activities. The columns include click status, timestamp, query term, IP address, cost per click, conversions, user and device. The goal is to come up with high level insights for managers to implement business strategies. Below is an outline of steps I’ve taken to complete the analysis:
- Read data
- Clean data
- EDA
- Export the cleaned dataset to Tableau and build charts for One Pager presentation from there
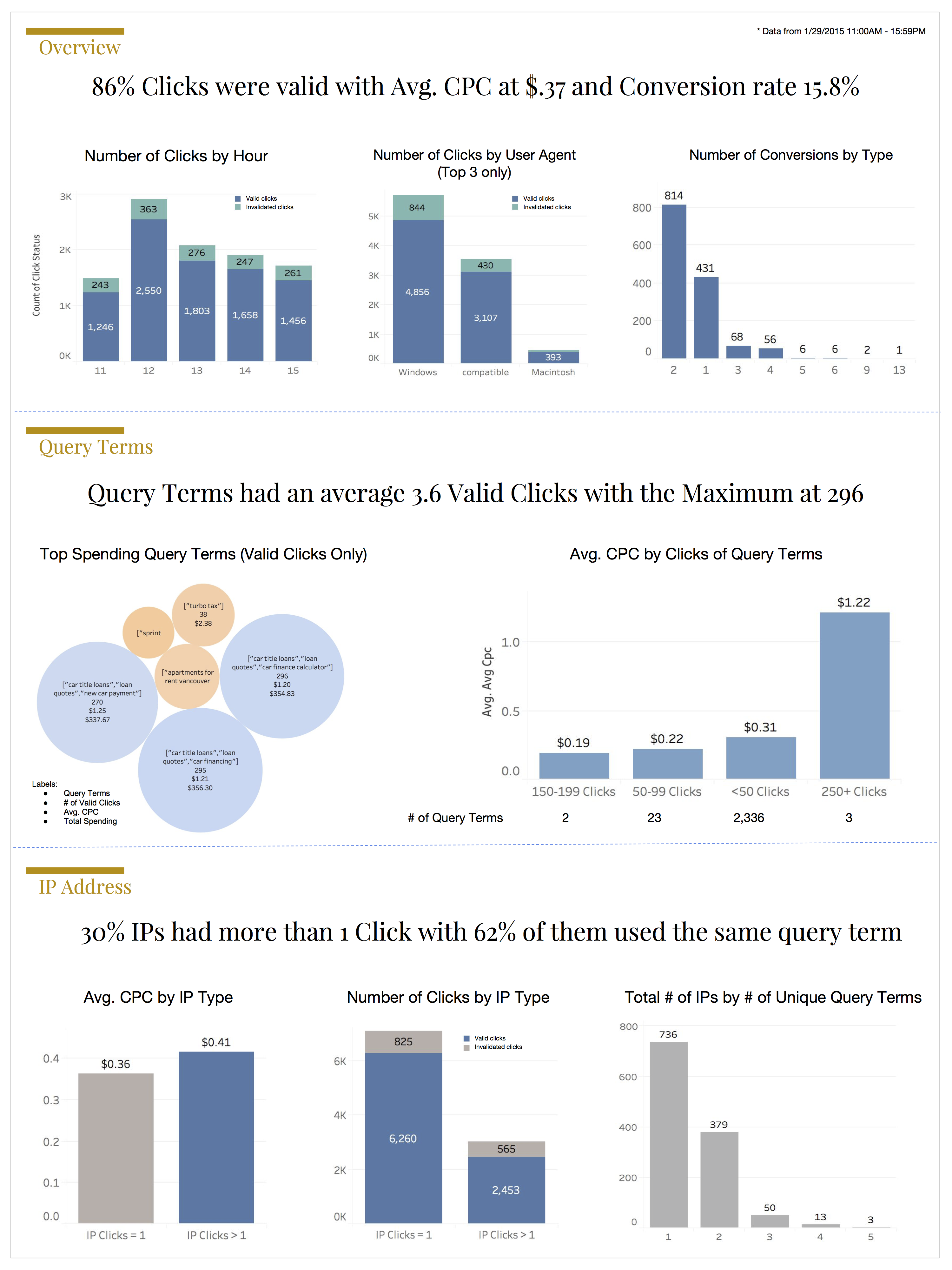
One Pager
I built this one-pager with cleaned dataset in Tableau
1. Read data
First, I used ‘text to column’ function in excel to clean up the ‘user agent’ column. Next I saved it as a csv file, so I can read the data into pandas dataframe
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn-white')
%matplotlib inline
df = pd.read_csv('Data-Analyst-Assignment-tab-cleaned.csv')
df.head()
| click_status | AMP_timestamp | Query Term | IP Address | Cost Per Click | Conversions | User | Device | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1/29/15 11:00 | ["michael kors","michael michael kors"] | 2.118.171.21 | $ .28 | 0 | Mozilla/5.0 | iPad |
| 1 | 1 | 1/29/15 11:00 | ["meet girls","dating girls"] | 0.82.173.102 | $ .17 | 0 | Mozilla/5.0 | Windows |
| 2 | 1 | 1/29/15 11:00 | ["meet girls","dating girls"] | 0.82.173.102 | $ .17 | 0 | Mozilla/5.0 | Windows |
| 3 | 1 | 1/29/15 11:00 | ["credit report","credit karma","free online c... | 219.32.49.92 | $ .90 | 0 | Mozilla/5.0 | Windows |
| 4 | 1 | 1/29/15 11:00 | ["Byethost"] | 13.54.12.142 | $ .17 | 0 | Mozilla/4.0 | compatible |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10103 entries, 0 to 10102
Data columns (total 8 columns):
click_status 10103 non-null int64
AMP_timestamp 10103 non-null object
Query Term 10103 non-null object
IP Address 10103 non-null object
Cost Per Click 10103 non-null object
Conversions 10103 non-null int64
User 10103 non-null object
Device 10099 non-null object
dtypes: int64(2), object(6)
memory usage: 631.5+ KB
2. Clean data
Noticed the dataset has 7 columns without missing values. In this section, I am going to clean all columns and create new features for further analysis.
Steps:
- Check NaN values and column names
- Clean click_status
- Clean AMP_timestamp
- Clean query_terms
- Clean cost_per_click
1. Double check NaN values and rename column names
# Check missing values - no NaN values
df[df.isnull().any(axis=1)]
| click_status | AMP_timestamp | Query Term | IP Address | Cost Per Click | Conversions | User | Device |
|---|
df.columns
Index([u'click_status', u'AMP_timestamp', u'Query Term ', u'IP Address',
u'Cost Per Click ', u'Conversions', u'User', u'Device'],
dtype='object')
# rename columns with extra space
df.columns = ['click_status','AMP_timestamp','query_term','IP_address','cost_per_click','conversions','user','device']
2. Clean click_status : click_status 1 = valid click, 0 = invalidated click
df.click_status = df.click_status.map(lambda x: 1 if x == 1 else 0)
3. Clean AMP_timestamp
- Extract date and hour
- Timestamp ranges from 1/29/15 11:00 - 1/29/15 15:59
df['date'] = df.AMP_timestamp.map(lambda x: x[:7])
df['hour'] = df.AMP_timestamp.map(lambda x: int(x[8:10]))
print 'max hour: ', df['hour'].max()
print 'min hour: ', df['hour'].min()
max hour: 15
min hour: 11
4. Clean Query Term
- 3 query terms related to car loans appeared on the top
- The # of query terms ranges from 1 to 7
df.query_term.value_counts().head(10)
["car title loans","loan quotes","car financing"] 317
["car title loans","loan quotes","car finance calculator"] 313
["car title loans","loan quotes","new car payment"] 290
["Byethost"] 268
["edu online info","degree programs","online degree program"] 176
["Naver.com"] 111
["ron"] 106
["apartments for rent vancouver craigslist","craigslist used cars","personals"] 88
["force download","youtuby","youtube org"] 87
["apricot complex"] 85
Name: query_term, dtype: int64
# Create a new column that stores query terms as a list
df['query_term_list'] = df.query_term.map(lambda x: x.strip('[').strip(']').replace('"','').split(','))
# Create a new column that indicates the length of the query terms list
df['len_query_term_list'] = df['query_term_list'].map(lambda x: len(x))
df['len_query_term_list'].value_counts()
3 4908
1 4016
2 826
4 139
5 122
6 91
7 1
Name: len_query_term_list, dtype: int64
5. Clean cost_per_click and converstions
df.cost_per_click = df.cost_per_click.map(lambda x: float(x.strip('$ ')))
df.conversions.value_counts()
0 8719
2 814
1 431
3 68
4 56
6 6
5 6
9 2
13 1
Name: conversions, dtype: int64
3. Analysis
1. High level trends
- Valid click rate at 86%
- Avg. CPC for valid clicks at .37
- Total spending for valid clicks 3,287
- Conversion rate 15.8%
df_1 = df[df.click_status == 1]
df_0 = df[df.click_status == 0]
# Valid click rate
len(df_1) / float(len(df))
0.8624171038305454
# Avg CPC for valid clicks
df_1.cost_per_click.mean()
0.3773258349592622
# Total spending for valid clicks
df_1.cost_per_click.sum()
3287.6400000000517
# Conversion rate for valid clicks
len(df[df.conversions!=0])/float(len(df_1))
0.1588431079995409
2. For clicks with status = 1:
- Identify the top spending query term and the average cost per click
- Identify the top converting IP addresses
# Identify the top spending query term and the average cost per click
qt_table = pd.pivot_table(df_1,index='query_term',values=['click_status','cost_per_click'],aggfunc=[np.sum]).sort_values(by=('sum','cost_per_click'),ascending=False)
qt_table[('avg','cost_per_click')] = qt_table[('sum','cost_per_click')] / qt_table[('sum','click_status')]
qt_table.head(10)
| sum | avg | ||
|---|---|---|---|
| click_status | cost_per_click | cost_per_click | |
| query_term | |||
| ["car title loans","loan quotes","car financing"] | 295 | 356.30 | 1.207797 |
| ["car title loans","loan quotes","car finance calculator"] | 296 | 354.83 | 1.198750 |
| ["car title loans","loan quotes","new car payment"] | 270 | 337.67 | 1.250630 |
| ["apartments for rent vancouver craigslist","craigslist used cars","personals"] | 81 | 97.11 | 1.198889 |
| ["turbo tax"] | 38 | 90.42 | 2.379474 |
| ["sprint wireless","sprint mobile","sprint","sprint wireless phones","cell phone","smartphone"] | 27 | 61.54 | 2.279259 |
| ["edu online info","degree programs","online degree program"] | 174 | 38.19 | 0.219483 |
| ["autotrader","autotrade","car website"] | 33 | 36.04 | 1.092121 |
| ["turbo tax","turbotax","intuit turbotax"] | 4 | 35.51 | 8.877500 |
| ["Byethost"] | 191 | 32.47 | 0.170000 |
qt_table.columns = ['valid_clicks','total_spending','avg_cpc']
bins = [0, 50, 100, 150, 200,250,300]
group_names = ['<50 Clicks', '50-99 Clicks', '100-149 Clicks', '150-199 Clicks','200-249 Clicks','250+ Clicks']
qt_table['click_bucket'] = pd.cut(qt_table['valid_clicks'], bins, labels=group_names)
qt_table.valid_clicks.mean()
3.6857021996615904
# Identify the top converting IP addresses
df_1[df.conversions != 0].IP_address.value_counts().to_frame().head(10)
/Users/KatieJi/anaconda/lib/python2.7/site-packages/ipykernel/__main__.py:2: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
from ipykernel import kernelapp as app
| IP_address | |
|---|---|
| 99.58.152.185 | 5 |
| 254.48.209.110 | 5 |
| 40.42.200.39 | 4 |
| 1.83.232.46 | 4 |
| 221.20.148.233 | 4 |
| 173.145.41.71 | 4 |
| 214.170.202.50 | 3 |
| 217.149.200.112 | 3 |
| 254.48.190.183 | 3 |
| 226.58.131.249 | 3 |
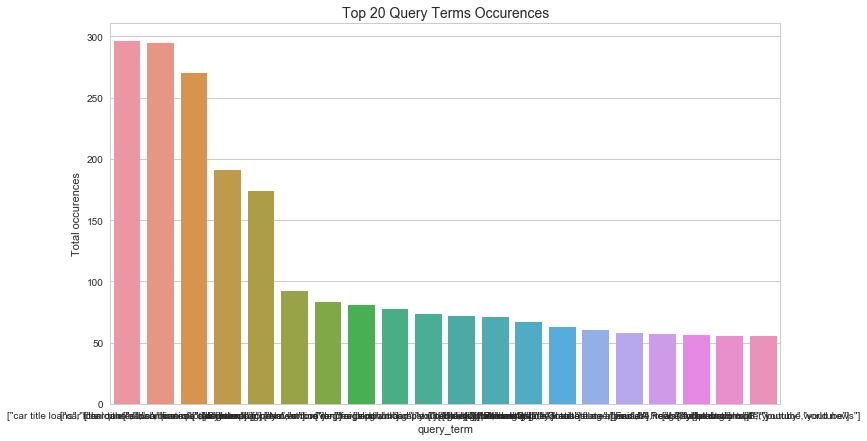
# Query terms table
fig,ax = plt.subplots(figsize=(12, 7))
sns.barplot(x = qt_table.head(20).index, y = qt_table.head(20)['sum'])
plt.ylabel('Total occurences')
plt.title('Top 20 Query Terms Occurences', fontsize=14);
total_num = float(len(qt_table))
for i in [1,5,10, 50, 100, 200]:
print '-- {:.2f}% of query terms had {} or more valid clicks'.format( (qt_table['sum'][qt_table['sum']>=i].count()) / total_num *100,i)
-- 91.38% of query terms had 1 or more valid clicks
-- 11.44% of query terms had 5 or more valid clicks
-- 5.37% of query terms had 10 or more valid clicks
-- 1.16% of query terms had 50 or more valid clicks
-- 0.19% of query terms had 100 or more valid clicks
-- 0.12% of query terms had 200 or more valid clicks
3. For IP addresses with > 1 click:
- Provide a breakdown on invalid and valid clicks. Include steps taken to conduct analysis
- Provide a breakdown on whether these users send the same query term for each click. Include steps taken to conduct analysis
- Identify any shared attributes for this pool of users (if any). Include steps taken to conduct analysis
ip_list = df.IP_address.value_counts()[df.IP_address.value_counts() >1].to_frame().index
df_ip = df[df.IP_address.isin(ip_list)]
# Provide a breakdown on invalid and valid clicks. Include steps taken to conduct analysis
ip_status_table = df_ip.click_status.value_counts().to_frame()
ip_status_table['percentage'] = ip_status_table.click_status / ip_status_table.click_status.sum()
ip_status_table
| click_status | percentage | |
|---|---|---|
| 1 | 2453 | 0.81279 |
| 0 | 565 | 0.18721 |
# Provide a breakdown on whether these users send the same query term for each click
ip_query_table = pd.pivot_table(df_ip,index=['IP_address','query_term'],values='click_status',aggfunc=[len]).reset_index()
ip_query_table.head()
| IP_address | query_term | len | |
|---|---|---|---|
| 0 | 0.38.12.224 | ["youtube","youtuby","r youtube"] | 1 |
| 1 | 0.38.12.224 | ["youtube","youtuby","youtube org"] | 2 |
| 2 | 0.53.181.217 | ["Nyanko Seek"] | 3 |
| 3 | 0.71.103.209 | ["meet girls","dating girls"] | 4 |
| 4 | 0.73.240.6 | ["Badidu"] | 2 |
ip_query_table_2 = pd.pivot_table(ip_query_table,index=['IP_address'],values='query_term',aggfunc=[len]).reset_index()
ip_query_table_2.columns = ['IP_address','unique_query_terms']
ip_unique_query = ip_query_table_2.unique_query_terms.value_counts().to_frame()
ip_unique_query['percentage'] = ip_unique_query.unique_query_terms / ip_unique_query.unique_query_terms.sum()
ip_unique_query
| unique_query_terms | percentage | |
|---|---|---|
| 1 | 736 | 0.623201 |
| 2 | 379 | 0.320914 |
| 3 | 50 | 0.042337 |
| 4 | 13 | 0.011008 |
| 5 | 3 | 0.002540 |
# Identify any shared attributes for this pool of users (if any)
# Create ip_clicks_status: 1 = IP addresses with > 1 click, 0 = IP addresses with 1 click
df['ip_clicks_status'] = df.IP_address.map(lambda x: 1 if x in ip_list else 0)
df['ip_clicks_status'].sum() / float(len(df['ip_clicks_status']))
0.2987231515391468
df.to_csv('cleaned_data.csv')